概要
AWS Glue は、分析を行うユーザーが複数のソースからのデータを簡単に検出、準備、移動、統合できるようにするサーバーレスのデータ統合サービスです。分析、機械学習、アプリケーション開発に使用できます。また、ジョブの作成、実行、ビジネスワークフローの実装のための生産性向上に役立つツールやデータ運用ツールも追加されています。
Glueのロールを作成
Glueのロールを作成します。
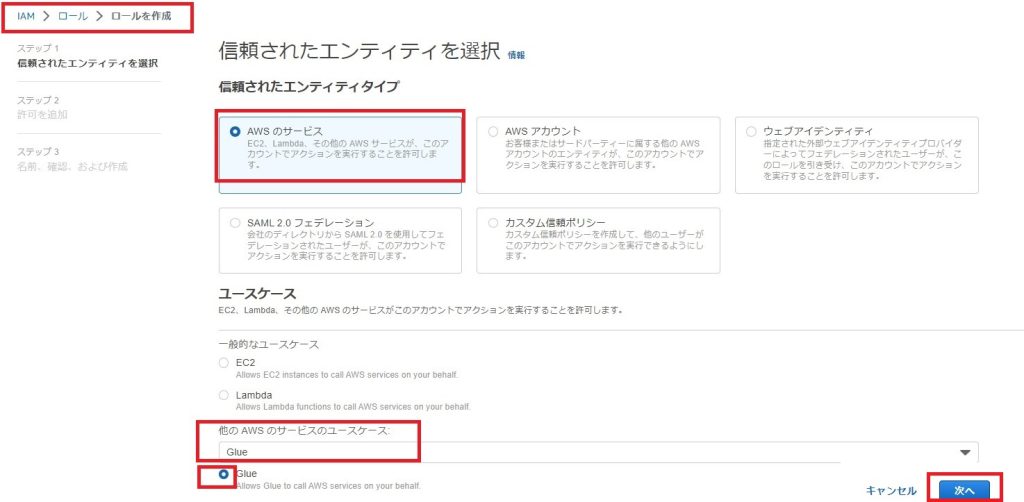
IAMコンソールのロール作成にて
「信頼されたエンティティタイプ」に「AWSのサービス」を選び
「ユースケース」にGlueを選びます。
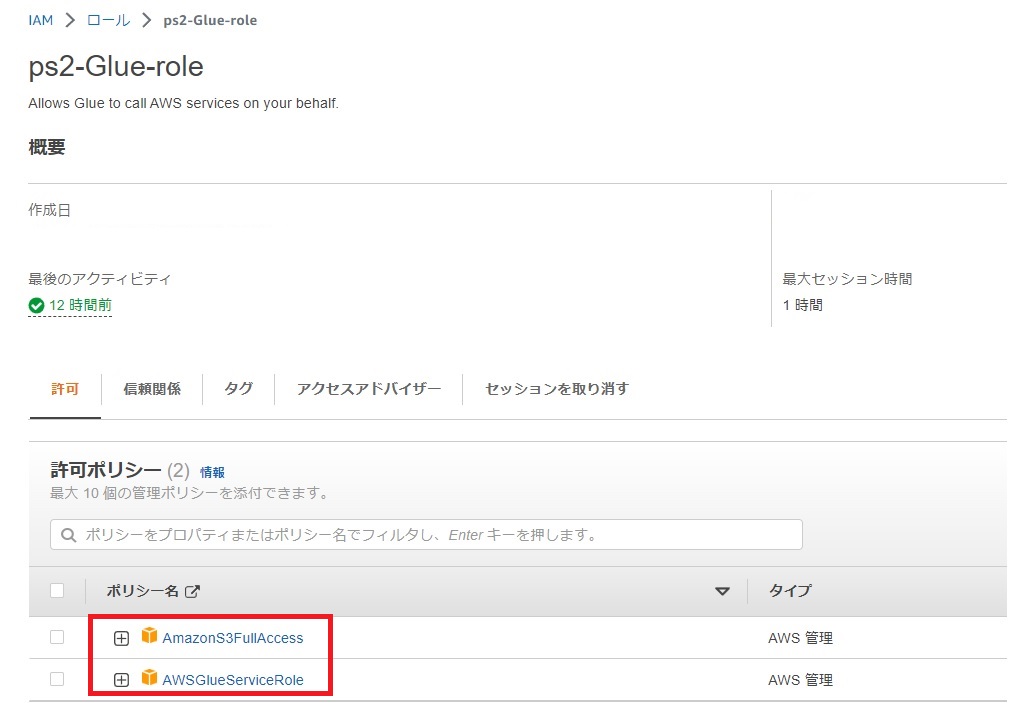
許可ポリシーにはAWS管理の
AWSGlueServiceRoleとAmazonS3FullAccessを追加します。
S3のフォルダを用意
Glueを自動で作成するとS3が勝手に作成されてしまうので、
その前に、意識的に、Glueのスクリプトファイルを置くフォルダとtempフォルダをS3に作成しておきます。
ここでは指定のS3に
s3://sample-xxxxxx/test-ps2-sample-glue-spark/scripts
s3://sample-xxxxxx/test-ps2-sample-glue-spark/temp
を作成しました。
Glue jobを作成
AWS Glue コンソールで [AWS Glue Studio]->[jobs]をクリックします。
SparkのGlue jobを作成します。
ここでは [Spark script editor]を選んでスクリプトを自作する設定にします。
[Create]をクリックします。
Scriptを作成
Script Editorが表示されます。
ここでは以下のスクリプトを記載しました。
スクリプトは後で編集できるので、ここでは簡単に書いておきます。
次に[job details]をクリックします。
Propertyを指定
Nameを指定します。
IAMロールに作成したGlueロールを指定します。
Glue versionを最新の4.0に指定します。
ここでGlue versionを2.0に指定した場合、Glue Version2.0は2024年1月にサポートが終了するので、3.0以降を使用しましょう。
下にスクロールして
[Advanced Properties]をクリックします。
Script filenameを指定します。
Script Pathとtemporary pathを、先ほど作成したS3にフォルダに指定します。
[Save]をクリックします。
これでGlue jobが作成されました。
Glueを実行
右上の[Run]をクリックするとGlue jobが実行します。
[Runs] をクリックすると結果が表示されます。
実行結果の確認
[Runs] をクリックすると結果が表示されます。
Glue Versionが表示されています。
また、実行結果のRuns statusが表示されます。
CloudWatch logsの確認
実行結果の[Output logs]をクリックすると、Glue jobの出力結果のCloudwatch logsに飛びます。
実行結果の[Error logs]をクリックすると、Glue jobのエラー結果のCloudwatch logsに飛びます。

出力結果
SparkのGlue jobの出力結果は
Cloudwath logsの/aws-glue/jobs/output
に出力されます。
エラー結果
SparkのGlue jobのエラー結果は
Cloudwath logsの/aws-glue/jobs/error
に出力されます。
CloudWatch logsの設定
ログ保持時間はデフォルトでは[失効しない]になっています。
Cloudwatch logsもコストがかかります。
そこで該当logの保持時間を編集します。
ここでは30日に設定しました。
失効時間を過ぎたログは削除されます。
AWS Cli commandで内容確認
Glue jobの内容を確認するコマンドは
$ aws glue get-job – job-name “name”
です。
以下のように表示されます。
Glue version=4.0
Glueを削除
Glue jobを削除した場合、削除してもs3上のスクリプトは残っています。
これも削除しましょう。
参考

